在前一篇中,我們學會了讓模型依照prompt一次接出多個字,但那樣的生成是固定的,模型永遠會選機率最高的那個token,接下來我們來改變生成策略,讓模型依照機率抽樣。
3. 改成按照機率來擲骰子,決定下一個token
在這個版本裡,我們不再強迫模型每次都挑機率最高的字,而是根據機率分佈隨機抽一個。
這樣能讓生成結果更多樣,不會每次都輸出一模一樣的句子。
流程:prompt ⟶ tokenizer.encode ⟶ input_ids ⟶ model ⟶ output ⟶ (按照機率擲骰子)token_str(prompt=prompt+token_str)重複length次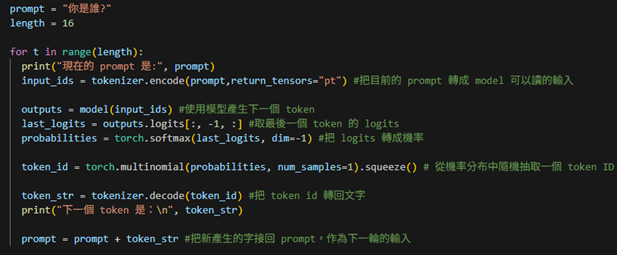
4. 改成只有機率前k名的才有參與擲骰子,決定下一個token是什麼
上一段的隨機抽樣雖然多樣,但有時會抽到機率太低的亂字。
為了讓結果更合理,我們改成只在前k名機率最高的token中抽樣,避免機率太低的字,同時保留多樣性。
流程:prompt ⟶ tokenizer.encode ⟶ input_ids ⟶ model ⟶ output ⟶top_p,top_indices⟶ (按照機率擲骰子)token_str(prompt=prompt+token_str)重複length次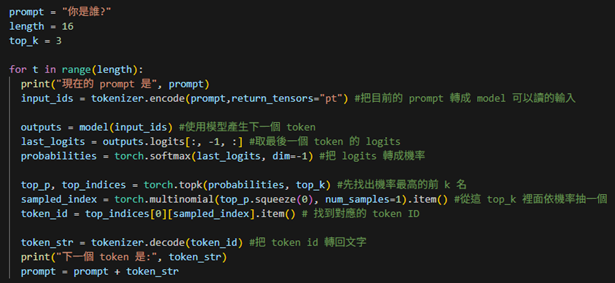
5. 用model.generate來做文字接龍,輸入的prompt連續產生多個token。
model.generate()可以把逐字預測和機率抽樣自動化,讓模型能自然地接下去說話。
前面的程式都在手動模擬預測下一個字,而在實務上,我們可以直接使用model.generate()來自動完成整個流程。
流程:prompt ⟶ tokenizer.encode ⟶ input_ids ⟶ model.generate ⟶ output ⟶ tokenizer.decode ⟶ generated_text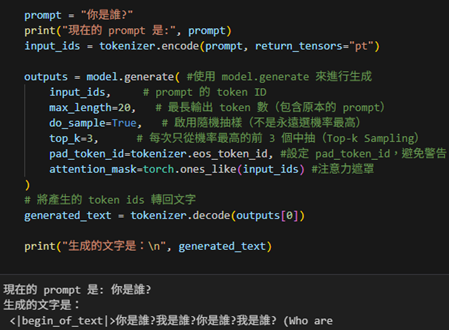
 妤
妤

 iThome鐵人賽
iThome鐵人賽